
In the high-stakes world of IT infrastructure, the difference between a minor glitch and a major outage is often measured in minutes. Yet, for most organizations, the incident response lifecycle remains stuck in a manual era. As cloud environments grow more complex and the global shortage of skilled IT professionals intensifies, the traditional approach to operations is reaching a breaking point.
To understand how Large Language Models (LLMs) are revolutionizing AIOps, we must first dissect the anatomy of a failure as it exists today and map out the architecture of the automated future.
This article analyzes the structural shift in IT operations by examining four critical stages of the incident lifecycle visualizing how we move from human bottlenecks to AI-driven orchestration and provides a technical blueprint for building these agents safely.
Here’s an outline of the article:
- The Current State
- The Structural Replacement (The Automation Concept)
- The Operational Architecture and Workflow
- Code Implementation: Building the Agent
- Navigating Challenges: Security and Hallucinations
- Future Directions
- Key Takeaways
The Current State
To solve the problem, we must first visualize the bottleneck. In traditional IT operations, there is a distinct gap between “System Detection” and “Human Action.”
The Incident Timeline
When a failure occurs, the monitoring system detects it almost instantly. However, the process immediately stalls. The alert sits in a queue until a human operator notices it,
confirms it is not a false positive, and begins the triage process. This gap between the machine detecting the issue and the human understanding is where Service Level Agreements (SLAs) are breached.
The Scope of Human Toil
Once the operator engages, they are burdened with a complex web of manual tasks. As illustrated in the paper’s analysis, the “Human Response Scope” involves switching context between multiple tools:
- Verification: Confirming the alert content.
- Log Retrieval: Manually SSH-ing into servers to pull error logs.
- Knowledge Retrieval: Searching wikis or calling support desks to see if this issue has happened before.
- Communication: Drafting emails to stakeholders to report the incident.
This manual workflow is error-prone and slow. The sequence diagram below visualizes this legacy process, highlighting the dependency on human bandwidth.
Figure 1: Current State Incident Response Sequence Diagram
The Structural Replacement (The Automation Concept)
The core proposition of modern AIOps is to replace the Human Operator with an Intelligent Agent.
Replacing the Operator
The objective is to remove the human from the initial response loop. Instead of an alert triggering a pager, it triggers an AI-Driven Automation Tool. This tool acts as the new operator. It doesn’t just forward the alert; it consumes the alert, gathers the necessary context, and passes it to an AI Service (LLM).
In this new paradigm, the human moves from being the doer (fetching logs, typing emails) to being the reviewer (approving the fix). This shift effectively collapses the time delay shown in the previous phase.
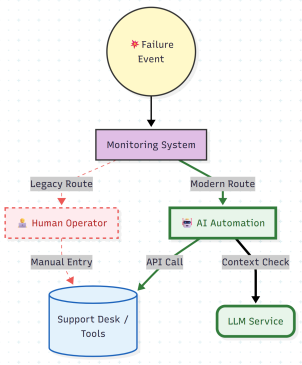
Figure 2: Before-versus-After Structure Proposition
The Operational Architecture and Workflow
How does this work in production? The final architecture reveals a complex interplay between the LLM, the operational tools, and historical data.
The Anticipated Workflow
This architecture relies on two distinct phases: Training (Preparation) and Inference (Response).
1. The Knowledge Ingestion (Training): Before the system goes live, the LLM is fine tuned or provided with a RAG (Retrieval Augmented Generation) database containing:
- Historical incident tickets.
- System logs from previous failures.
- Runbooks and tribal knowledge from the support desk.
Why this matters: This ensures the AI isn’t guessing; it is applying institutional memory to the current problem.
2. The Autonomous Loop (Inference):
- Trigger: The Monitoring Service detects a failure.
- Orchestration: The Automated Query Tool receives the alert.
- Log Ingestion: It uses an API to pull real-time logs from the affected machine (Infrastructure).
- Reasoning: It sends the Error Message + Real-time Logs to the LLM. The LLM correlates this with the Knowledge Base to identify the Root Cause.
- Action: The LLM directs the Email Tool to draft a notification and the Operation Tool to execute remediation commands for reporting purposes.
The diagram below details this end-to-end workflow flow.
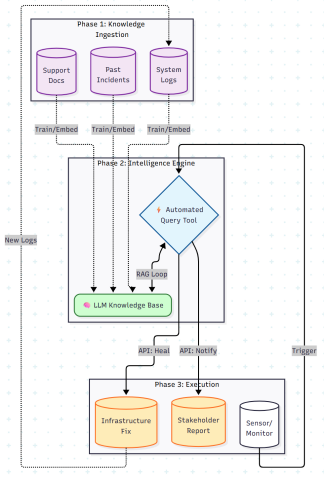
Figure 3: End-to-end Operational Flow
Code Implementation: Building the Agent
To visualize how this works technically, consider a simplified Python example using a framework like LangChain.
The agent utilizes tools to interact with the infrastructure, mirroring the API connections.
Algorithm: Python code using LangChain For Building the Agent
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
from infrastructure_tools import fetch_server_logs, check_cpu_usage, restart_service # Define the tools the LLM can use (The "Hands" of the system)
tools = [
Tool(
name="Fetch Logs",
func=fetch_server_logs,
description="Useful for retrieving raw error logs from a specific server ID." ),
Tool(
name="Check CPU",
func=check_cpu_usage,
description="Checks current CPU load."
),
Tool(
name="Restart Service",
func=restart_service,
description="Restarts a system service. Use with caution."
)
]
# Initialize the LLM (The "Brain")
llm = OpenAI(temperature=0) # Low temperature for deterministic outputs # Initialize the Agent
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# Simulate an incoming alert from the monitoring system
incoming_alert = {
"server_id": "srv-prod-04",
"error_msg": "502 Bad Gateway - Connection Refused",
"timestamp": "2025-12-27T03:14:00Z"
}
# The Agent executes the reasoning loop
prompt = f"System alert received: {incoming_alert}. Investigate the logs and suggest a fix."
response = agent.run(prompt)
print(response)
# Output might look like:
# "I have fetched the logs for srv-prod-04. The logs indicate the Nginx service has crashed due to memory overflow. I recommend restarting the Nginx service."
Navigating Challenges: Security and Hallucinations
While the potential is immense, deploying Generative AI in production infrastructure requires strict guardrails.
- The Hallucination Risk: LLMs can confidently sound wrong. In an IT context, a “hallucinated” command could delete a database. To mitigate this, the system should operate with a Human-in-the-Loop (HITL) for critical actions. The AI performs the investigation and proposes the fix, but a human engineer approves the execution of write-commands until the system proves its reliability.
- Data Privacy and Security: Infrastructure logs often contain sensitive IP addresses, internal hostnames, or even leaked PII. Before any log data is sent to an LLM (especially if using a public API model), it must pass through a Sanitization Layer. This layer uses regex or Named Entity Recognition (NER) to mask sensitive data (e.g., replacing an IP with [IP_ADDRESS_1]).
- Transparency: The Black Box problem is real. Operators need to know why the AI suggests a restart. The system must cite its sources: “I recommend this fix because it successfully resolved a similar incident (Ticket #4092) on March 12th.”
Future Directions
The evolution of this technology points toward Proactive Self-Healing. Instead of waiting for a failure, future iterations will analyze trend data to predict outages before they occur. By identifying “pre-incident” log patterns, the Agent could scale up resources or rotate credentials proactively, preventing the downtime entirely.
Furthermore, we will see a move toward “Small Language Models” (SLMs) fine-tuned specifically for DevOps tasks. These models will be smaller, faster, cheaper to run, and capable of running on-premises to alleviate data privacy concerns.
Key Takeaways
- Reduction in MTTR: By automating the initial triage and log gathering, response times can be cut from hours to minutes.
- Knowledge Democratization: The LLM acts as an institutional memory bank , allowing junior engineers to solve complex problems using the collective wisdom of the organization.
- Scalability: AI agents can handle hundreds of simultaneous alerts, preventing the bottleneck that occurs when human teams are overwhelmed during major outages.
- Guardrails are Essential: Implementation must prioritize data sanitization and human oversight to ensure safety and security.
The transition to LLM-powered AIOps is not merely about installing a chatbot; it is about fundamentally re-wiring the data flow of incident response to let machines handle the data, so humans can handle the decisions.
The text was delivered by Dippu Kumar Singh, Senior Solutions Architect at Fujitsu Americas and a speaker at upcoming Data Science Salon Austin conference on February 18. Secure your spot!